Web
web1
思路是先上传一个执行命令的jar包,打两次才可以,第一次让JVM加载个恶意反序列化类,但是不会触发类加载,得第二次反序列化那个类才会去加载。
web2
?lyrics=***存在任意文件读取,首先访问/lyrics?lyrics=/usr/etc/app/app.py,
/lyrics?lyrics=/usr/etc/app/cookie.py得到源码
|
|
cookie.py
|
|
/lyrics?lyrics=/usr/etc/app/config/secret_key.py下得到secret_code
一眼pickle反序列化,思路跟去年差不多,不过waf过滤了R指令,所以用o指令伪造session传递到pickle反序列化那弹shell。
Pwn
pwn1
一道板子栈溢出+栈迁移 迁移到bss段就行了 注意地址不要太低 否则会操作到不可写地址
|
|
pwn2
一道堆风水的屌丝菜单题
size限制的比较死 edit也只有一次机会
通过最后一个功能很容易获得这次edit的机会
漏洞很明显 free的时候指针未清除
那么把堆块大小分为大中小
Leak addr
通过构造大小两堆块 ,再相继free掉 在原来的地址申请两个中堆块 free前的指针残留了 而show检测的城市可以是起始点和目的地一致 恰好原位置对应索引都是0 简单show变能得到后面中堆块(也要free 可得到libc和heap地址)的残留地址
hijack
由于程序留了个edit 简单构造一下 glibc版本是2.35,打house of apple 拿edit功能写残留指针到largebin去完成
EXP
|
|
pwn3
popen命令执行 过滤了一些特殊符号 但是影响不大
很多思路 一个思路是将/flag cp 进/home/ctf/html,再直接读取即可
pwn4
一道沙盒题 UAF+house of apple劫持执行流板子题就不多说了
之后的沙盒部分详见博客记2024羊城杯的一道沙盒pwn题
pwn5
一道c++异常机制的板子题
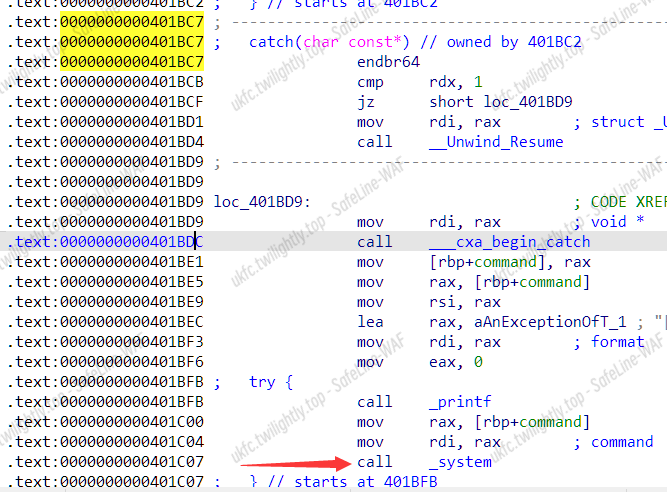
题目内有后门 但是需要控制参数 而参数在功能1可覆写
了解原理后 功能2中进行栈溢出 控制bp为可写区域 返回地址为0x401bc7
在unwind堆栈回溯时即可跳转到这里继续执行
|
|
Misc
misc6
相同思路的一道题:https://blog.csdn.net/weixin_42831646/article/details/127989608
文件名字解base64得到shift!
该磁盘文件使用FTK挂载,发现需要密码。先010查看得到

进一步通过刚刚得到的shift!推测出密码是!@#$%^&
挂载成功得到
发现修改日期不是19就是20,推断为0或1的二进制,转换后得到the_key_is_700229c053b4ebbcf1a3cc37c389c4fa
使用Encrypto解密得到flag
Crypto
Reverse
plc
ida打开 patch掉反调试
首先读取输入,若长度不为5则退出
然后将输入作为rc4密钥进行s盒置换
|
|
首先获取flag.png 然后将数据与输入的第二个字符异或后进行魔改rc4加密
rc4是单字节加密,且png文件头前八位不变,可以利用010读取加密过的flag文件头,然后仿写算法对密钥进行爆破
|
|
爆破得到密码为0173d 利用rc4加密对称性,输入0173d即可还原flag
docCrack
宏VBA密码工程文件密码破解 - 『脱壳破解区』 - 吾爱破解 - LCG - LSG |安卓破解|病毒分析|www.52pojie.cn
破解后看里面函数
|
|
使用bat创建了一个temp.exe 执行后删除
我们修改代码使其可见并不被删除 执行宏 拖入ida
|
|
结果均为可见字符,这里随便猜一下是异或,将前六位异或“DASCTF”发现结果均为7
|
|
得到flag
你这主函数保真吗
找到加密逻辑在__static_initialization_and_destruction_0函数里
挨个看,发现首先对输入进行ROT13,再进行离散余弦变换后与密文比较
|
|
rustVM
题目难度简单 直接ida打开,看一眼逻辑
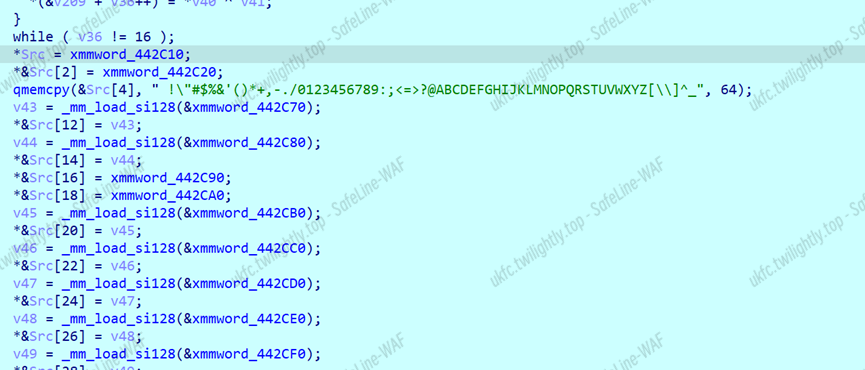
进行一些初始化操作,随便输入一点东西动态调试跑起来
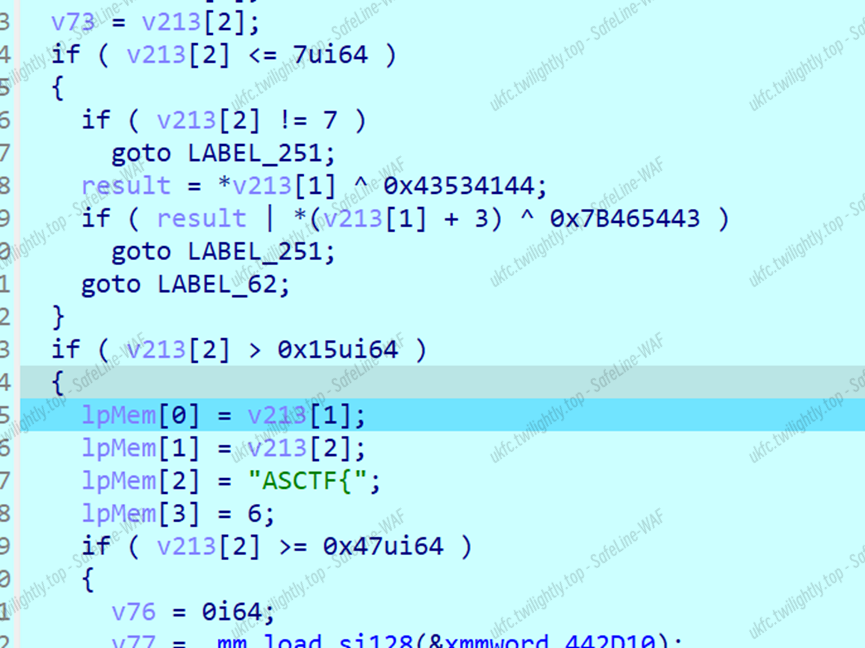
这里进行长度检测和头尾检测,然后异或值匹配头部和尾部
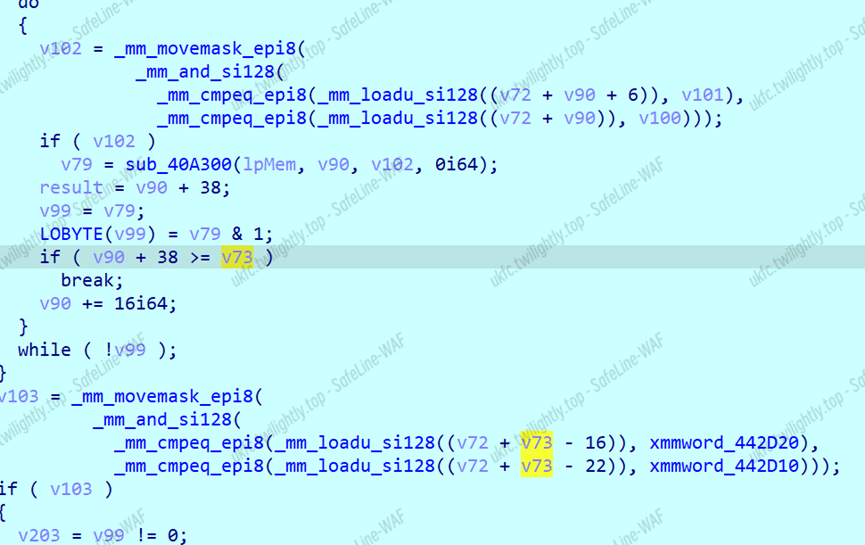
同样是比较头尾和检验长度的操作,应该是混淆
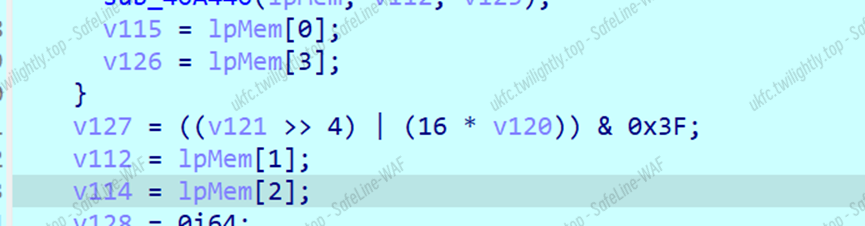
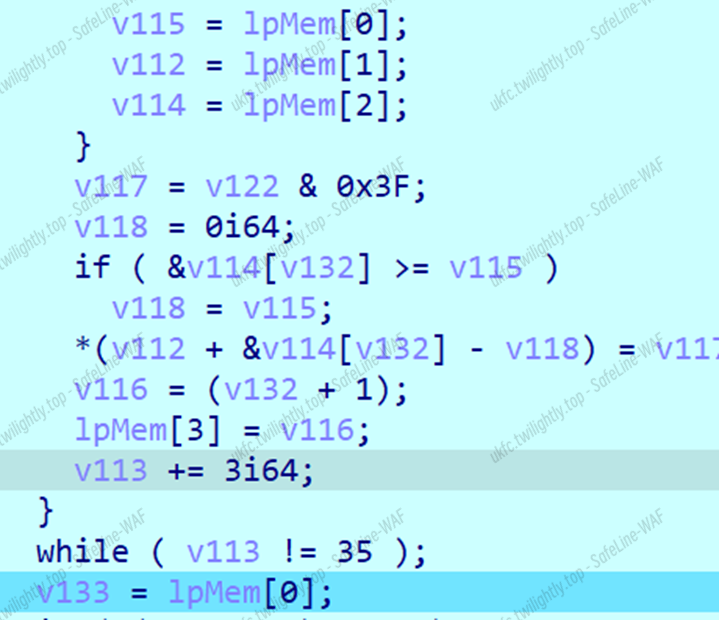
这里有一大坨0x3f加上位运算,调试发现是对输入base64

然后传入关键函数,这个函数多次出现,flag经过base64转化为base64_res传入

找到关键的vm函数,进行简单分析
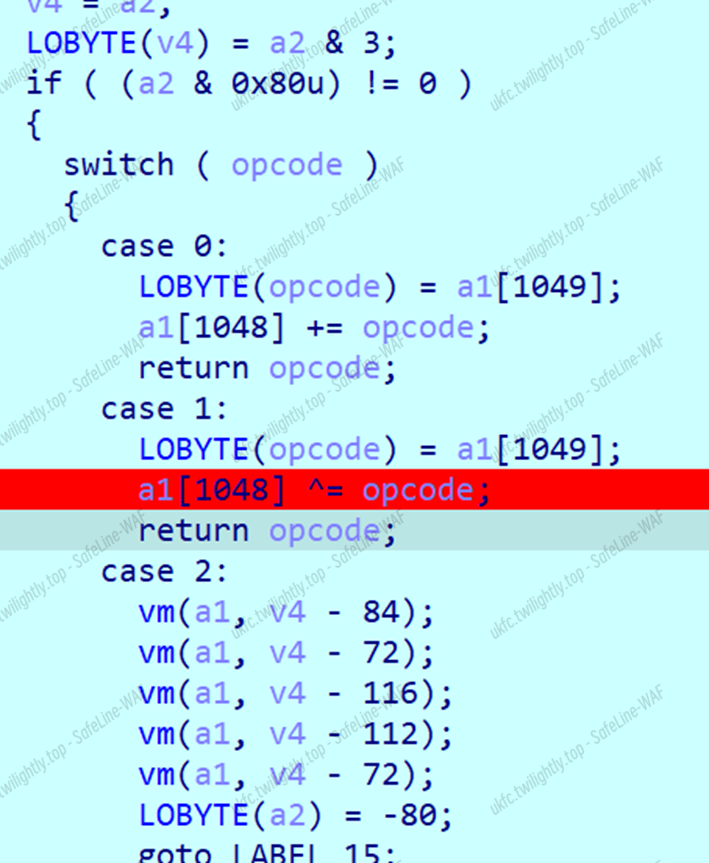
这里的opcode比较复杂,不同二进制位控制不同流程,上两位控制最外层,下位控制数组下标,这里写了一个加法器和一个异或器,下面还有一大堆重复调用,调试后发现a1[1048]决定a[1052]的大小,而在check里a[1052]必须为0,调试其他函数发现加法器并不影响值,直接断在异或处,反复调试拿到数据,异或一把梭。
|
|
(还有frida爆破和ponce爆破的方法,未完待续)
数据安全
1
直接根据数据特征排序数据
|
|
2
使用wireshark导出所有json的http数据包,发现最多导出1000条。
经过尝试,没有解决这个问题,改为把所有json数据,保存为pcapng文件。
手动编辑文件,只保留可见字符,编写脚本提取数据。
|
|
对提取后的数据根据规范清洗数据。
|
|
3
观察log日志,编写脚本提取数据
|
|
对提取出的数据验证格式
|
|
数据脱敏
|
|
